August 06, 2021
Seismic data is a key component in the E&P industry; however, accurate measurement of subsurface parameters is usually acquired through well logging. Let’s look at the differences between these two types of data.
Well data is recorded in depth but is spatially limited, whereas seismic data coverage is comparatively large and usually covers the entire field. But because seismic data is recorded in the time domain, this renders domain conversion of seismic data a vital component of accurately planning a well and estimating the reserves and business value of a field.
Velocity modeling is a proven methodology for seismic domain conversion (i.e., time to depth), however, it requires extensive subject matter expertise and complex workflows. Not only that, there is a chance of uncertainties being introduced into the model during the workflow.
A data-driven, Artificial Intelligence (AI) and Machine Learning (ML) based solution can address these uncertainties by replicating the most effective and efficient procedures throughout the learning stage of the algorithm. This helps ensure optimal depth converted seismic data. Interestingly, this methodology does not require a velocity model to convert seismic data, as the conversion happens on a trace-to-trace sample level.
This novel approach demands only a smaller area in terms of time and depth domains within the seismic data for training the algorithm. The assumption behind the approach is that when the depth converted seismic data is validated with well-well stretch correction, geology does not vary significantly outside the training area and most importantly, both the seismic data are of the same quality.
If the geology shows severe lateral variation beyond the training area, an additional training set is required to achieve accurate conversion.
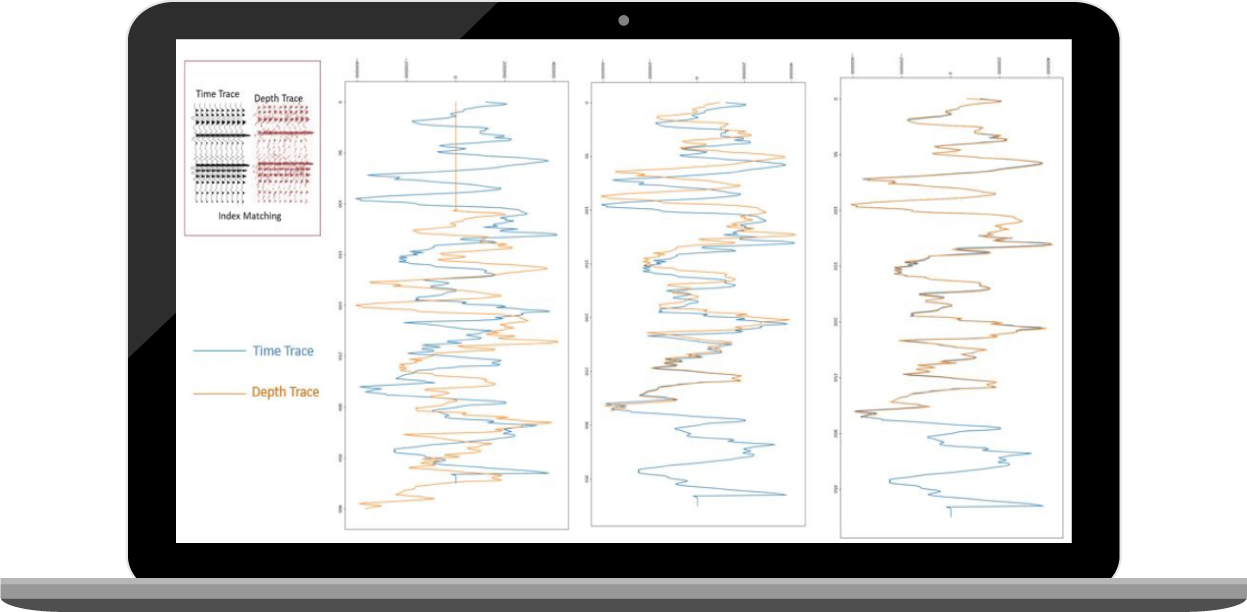
The data-driven methodology starts with a training area comprised of 10-20 percent of the total area (volume). The remaining 80-90 percent area (volume) can be called a test area. Seismic data normalization is done for both the time and depth domain seismic after routine data pre-processing and data cleaning. A few seismic attributes are calculated next and, based on the domain knowledge, the attributes are selected to represent the best acoustic velocity variation in the subsurface. The most critical component of the workflow is called trace matching – this involves time seismic trace and depth seismic trace match for their indices based on the same motif. A unique algorithm is developed to execute this step utilizing the advanced computational techniques and machine learning concepts.
In the chart below (Figure 1), the algorithm handles the challenge of Trace Indices Matching (TIM) quite reliably. Once this step is completed, the algorithm gets ready to learn about the time to depth conversion. Representing seismic attributes as ML modeling features helps to correlate the velocity variation in the subsurface.
This methodology also utilizes geological faults as fault polygons to act as a data-leakage control. Building velocity models for highly faulted or thrusted geology can be quite challenging and this AI-driven solution can be considered as an effective tool even for complex scenarios.
The result suggests that the variation of ML-driven domain conversion remains within +/- 5 percent compared to conventional velocity model-based domain conversion. At the same time, the workflow cycle time gets reduced from weeks to hours.
In summary, this AI-driven method for seismic domain conversion presents a strong alternative to traditional models. This innovative technique maintains consistency and ensures that the best practices within the organization are implemented in near real-time for any additional data sets of similar geological characteristics. This solution is also cloud native and can be implemented for both pre-drill and post-drill domain conversion of the seismic data. As the model replicates, the results produced through best practices help reduce ambiguity and deliver higher business value.